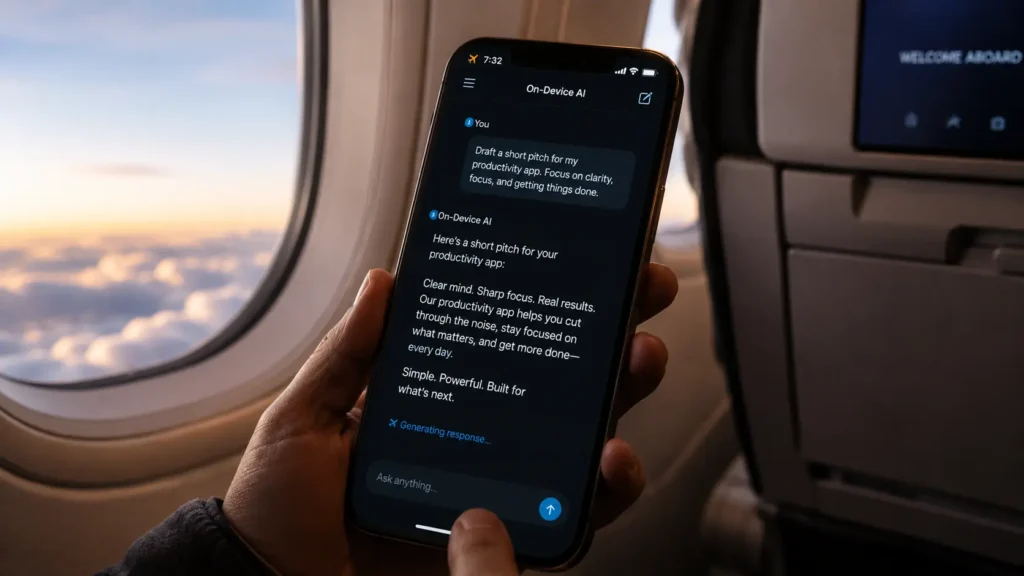
For the last three years, every major AI feature on your phone has required one thing: a signal. Your query leaves your device, travels to a server farm somewhere, gets processed by a model running on thousands of chips, and comes back as an answer. It’s fast enough that you don’t notice the round trip. But it’s happening every single time.
The iPhone 17 Pro is built to end that dependency. And the chip making it possible the A19 Pro is unlike anything Apple has shipped in a smartphone before.
The Chip That Changes the Conversation
The A19 Pro is a 64-bit ARM-based system on a chip manufactured by TSMC using the N3P variant of their 3nm process node. It features a 6-core CPU, a 6-core GPU with Neural Accelerators built into each core, and a 16-core Neural Engine with improved memory bandwidth compared to the A18 generation.
The A19 Pro features 12GB of LPDDR5X memory running at 9600 MT/s, with memory bandwidth of up to 76.8 GB/s. The Apple10 GPU architecture introduces doubled FP16 performance compared to previous generations and includes dedicated tensor processing units Neural Accelerators optimized for matrix multiplication operations in machine learning workloads, enabling approximately 4x the peak GPU compute performance on the A19 Pro compared to the A18 Pro.
That last number is the one that matters most. Matrix multiplication is the core operation in every large language model. Quadruple the performance there, and you’ve fundamentally changed what a phone can do with AI locally.
Running a 7B Model – On a Phone, Offline
The headline claim isn’t marketing language. It’s engineering reality.
The iPhone 17 Pro with A19 Pro can achieve 22.3 tokens per second with optimized models, providing responsive local AI performance. For context, that’s a conversational speed fast enough to feel like a real-time exchange rather than a loading spinner.
Apple’s strategic objective with the A19 generation is enabling iPhone to run GPT-3.5-class models entirely on-device a capability that represents a fundamental shift in how AI services are delivered on mobile. A 7-billion parameter model sits squarely in that class. These are the same models that, two years ago, required a dedicated server to run.
Apple has significantly increased the priority for achieving market-leading performance for large Transformer inference workloads with the A19 Pro. Most of these improvements come out-of-the-box with iOS 26.
The combination of the Neural Engine, the GPU’s Neural Accelerators, and 12GB of high-bandwidth memory creates a three-layer AI processing stack that no previous smartphone has had. Each layer handles different parts of the workload the Neural Engine optimizes for energy efficiency, the GPU’s Neural Accelerators handle raw throughput, and the memory bandwidth ensures neither is starved of data.

The Thermal Problem Apple Finally Solved
Running a 7B model continuously does one thing immediately: generates heat. A lot of it. And heat, on a device you hold in your hand, translates to throttling the processor slowing itself down to avoid damage.
This is the engineering problem that made sustained local AI inference on phones feel like a promise that never quite delivered. Previous iPhones could start running demanding AI workloads at full speed. Sustaining that speed was another matter.
Apple addressed this directly with an Apple-designed vapor chamber containing deionized water, laser-welded into the aluminum unibody that moves heat away from the A19 Pro chip. When paired with this thermal system, the A19 Pro enables iPhone 17 Pro to deliver up to 40 percent better sustained performance than the previous generation.
The vapor chamber works with the aluminum unibody structure to efficiently distribute heat across the entire chassis not just away from the chip, but through the frame of the phone itself. The deionized water inside carries thermal energy at speeds 20 times greater than the titanium used in previous Pro models.
The result: a phone that can maintain full AI inference performance for extended periods without throttling. That’s not a small achievement. That’s the difference between a demo and a real product.
What This Means for Privacy and Why It Matters More Than Speed
The performance story is compelling. The privacy story is more important.
Every query you’ve ever sent to a cloud AI has, by definition, left your device. Your questions, your documents, your context all of it transmitted to third-party servers, processed, logged, and stored under terms of service most people have never read.
Local AI inference changes that equation completely. When the model runs on your device, your data never leaves. There’s no server to breach. No company to subpoena. No outage to wait out. The AI is yours, running on hardware you own, processing information that never moves.
The A19 Pro’s Neural Engine enables faster Siri responses with on-device processing, improved photo editing with AI-enhanced image recognition, and better predictive text and real-time language translation all handled locally.
Apple has been building toward this for years. The Neural Engine debuted in 2017 with 0.6 TOPS. The A19’s Neural Engine now processes 38 trillion operations per second. That’s a 63,000x increase in AI processing power across eight generations all pointing toward the moment when the phone doesn’t need to ask the cloud for help.
That moment is here.

The Developer Opportunity
In real-world benchmarks, iPhone 17 Pro is already up to 3.1x faster than iPhone 16 Pro on iOS 26 for large Transformer model inference on the GPU with the new Neural Accelerators.
The Neural Engine remains the clear choice for on-device inference due to faster inference with better energy efficiency, all-day battery life, and no resource contention with traditional workloads.
For developers, this opens territory that simply didn’t exist before. Applications that previously required cloud connectivity real-time translation, document analysis, code generation, intelligent search across private data can now run entirely on-device. A translation app that works in airplane mode. A writing assistant that never sends your drafts to a server. A coding tool that reads your proprietary codebase without uploading it anywhere.
The A19 Pro includes Memory Integrity Enforcement a hardware and software-based memory safety system utilizing ARM’s Enhanced Memory Tagging Extension providing an additional layer of security for sensitive on-device AI workloads.
The Bigger Picture
The smartphone has been getting faster for fifteen years. But faster at the same things loading apps, rendering graphics, processing images starts to feel incremental after a while.
Running a 7B AI model locally isn’t incremental. It’s a category shift. The phone stops being a terminal that connects to intelligence elsewhere and becomes the intelligence itself.
The A19 Pro is Apple’s most capable iPhone chip yet ideal for gaming, video editing, and running large local language models. That last item on Apple’s own list tells you everything about where the company sees the next five years going.
The cloud isn’t going away. But for the first time, your phone doesn’t need it.
© AiwalaNews | Global Tech & Privacy Edition | May 2026
Read Also:
- 🔗 Apple Intelligence Explained: What A19 Pro Actually Does With Your Data
- 🔗 On-Device AI vs Cloud AI: Why the Shift Is Bigger Than You Think