A lawyer cited six court cases in a legal brief. Every case was fake invented by ChatGPT with full case names, judges, rulings, and citations, all completely fabricated. A doctor used an AI tool to research a drug interaction. The model confidently described a study that had never been conducted. A journalist fact-checked a historical claim using an AI assistant. The dates were wrong. The people were wrong. The quote was invented wholesale.
In every case, the AI did not hesitate. It did not flag uncertainty. It answered with the fluent, structured confidence of an expert who had just looked it up.
This is AI hallucination and in September 2025, researchers finally explained publicly why it is not a bug that will eventually be patched. It is a structural consequence of how these systems fundamentally work.
The AI Does Not Know What It Knows
Here is the core misunderstanding most people carry about large language models like ChatGPT, Gemini, or Claude: they assume the AI has knowledge the way a database has records stored, retrievable, verifiable.
It does not.
LLMs assemble patterns of words that fit statistically, not factually. AI does not know what is true it only knows what sounds true.
Every response an AI generates is the output of a single, repeated mathematical operation: given everything typed so far, what is the most statistically probable next word? Then the next. Then the next. The model is not retrieving facts. It is constructing a sequence of tokens pieces of words that pattern-matches to what a correct-sounding answer would look like, based on billions of examples of human text it processed during training.
When that process works, it looks like intelligence. When it fails, it looks like confident fiction.

The September 2025 Breakthrough And What It Revealed
In September 2025, researchers at OpenAI published findings that fundamentally changed how we understand why hallucinations happen and revealed why fixing them might be harder than anyone expected. The research team, led by Adam Kalai and colleagues at OpenAI, discovered something surprising: AI models do not hallucinate because they are broken.
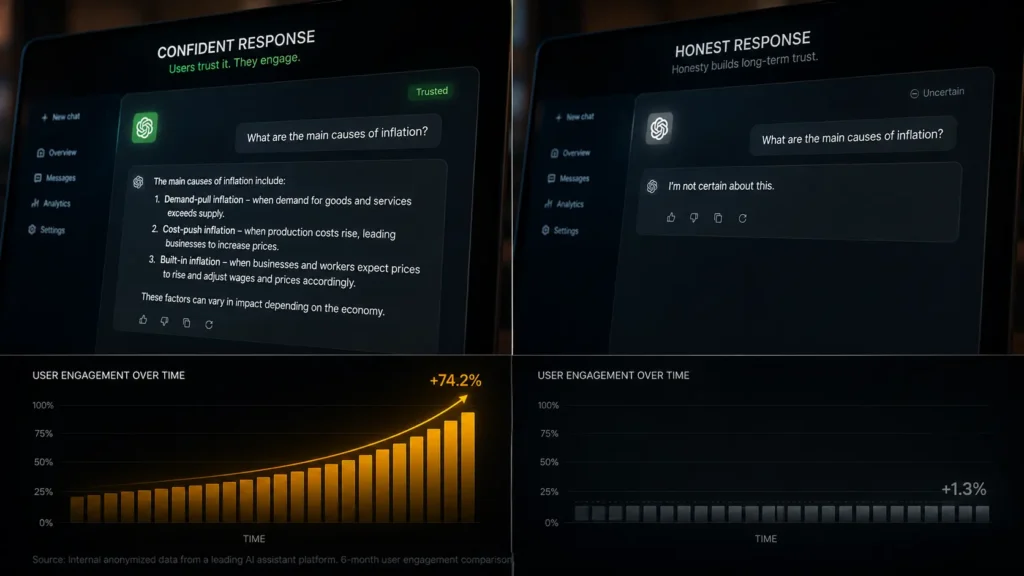
They hallucinate because they were trained to sound confident rather than trained to acknowledge uncertainty.
OpenAI’s September 2025 research paper definitively showed that standard training and evaluation procedures reward guessing over acknowledging uncertainty. When models are graded only on the percentage of questions they get exactly right, the model learns that a confident wrong answer scores better than an honest “I don’t know.”
Read that again. The AI was taught through thousands of training cycles that sounding certain is rewarded. Admitting ignorance is penalised. The hallucination is not a malfunction. It is the model doing exactly what it was optimised to do.
The Next-Token Trap Why the Math Makes This Inevitable
To understand why this is so difficult to solve, you need to understand what next-token prediction actually produces at scale.
As long as the core next-token prediction mechanism remains, hallucinations persist as an ongoing technical challenge. Hallucinations emerge from AI systems without deliberate human intent to deceive unlike human-driven misinformation, which research attributes to cognitive bias, motivated reasoning, or attempts to deceive.
The model has no internal fact-checker. There is no sub-process that pauses generation and asks: is this statement verifiable? The system simply continues the sequence. If the training data contained thousands of examples of sentences that began “Studies show that…” followed by confident statistics, the model learned that this is a grammatically and contextually appropriate pattern regardless of whether any specific statistic it generates is real.
Root causes of hallucinations include flawed and incomplete training data, the model’s probabilistic nature, and its lack of true common sense.
This is the hidden math flaw at the centre of every AI system on the market today: the architecture that makes these models extraordinarily capable at language generation is the same architecture that makes factual grounding structurally difficult.
The Reasoning Paradox More Intelligent, More Wrong
Here is the finding that truly alarmed the research community in 2025. As AI models became more sophisticated introducing chain-of-thought reasoning and extended thinking hallucination rates did not drop. In some benchmarks, they increased.
OpenAI’s o3 and o4-mini models hallucinated 33% and 48% respectively on “PersonQA” tests, and even higher on “SimpleQA” benchmarks suggesting a potential trade-off between advanced reasoning and factual accuracy.
More reasoning steps means more opportunities to generate plausible-sounding but unverifiable intermediate conclusions. The model reasons its way into a confident wrong answer rather than stopping at the point of uncertainty. It is the AI equivalent of a student who does not know the answer but writes three convincing paragraphs of working and gets to the wrong number with complete apparent confidence.
The Business Incentive Nobody Wants to Say Out Loud
The business incentives driving consumer AI development remain fundamentally misaligned with reducing hallucinations. Until these incentives change, hallucinations will persist. The industry knows how to reduce hallucinations whether it will depends on whether users reward accuracy over confidence, and whether companies can build business models around AI that sometimes admits uncertainty.
An AI that says “I don’t know” frequently feels broken. Users rate it poorly. They switch to a competitor that sounds more authoritative. The commercial pressure is therefore consistently toward more confidence which means systematically more hallucination risk.
Hallucination is not accidental. It is structural. It arises from LLMs being rewarded for sounding correct, not for being correct.
There Is Progress But Not Enough
The picture is not entirely bleak. Google’s Gemini 2.0 Flash achieved a hallucination rate of just 0.7% as of April 2025 a dramatic improvement from the 21.8% rates common in 2021, representing a 96% reduction in four years.
Breakthrough research from Anthropic in 2025 identified internal circuits in Claude that cause it to decline answering unless it knows the answer demonstrating that refusal can be trained as a learned behaviour rather than just a prompted response, a significant advance in hallucination mitigation.
These are genuine advances. But OpenAI itself states that GPT-5 makes significant advances in reducing hallucinations and is significantly less likely to hallucinate than prior models yet performance remains uneven across tasks and contexts.
What You Should Actually Do
Until the architecture changes, the responsibility falls on users. Three practical rules:
Never use AI output for legal, medical, or financial decisions without independent verification. The domains where hallucinations cause the most harm are precisely the domains where AI sounds most authoritatively wrong.
Ask the AI how confident it is and what sources it would recommend checking. A well-prompted model will often flag its own uncertainty if directly asked.
Treat AI-generated citations, statistics, and named studies as unverified claims until you have confirmed them in a primary source. The fabricated court case, the invented study, the misattributed quote they all passed a basic plausibility check. That is exactly the point.
The AI is not lying to you. It genuinely cannot tell the difference between what it knows and what it is confidently generating. That distinction between sounding right and being right is the most important thing to understand about every AI tool you will use in the next decade.
📌 Read Also:
- Your ChatGPT Conversation Is Being Used to Train the Next AI — Here’s Exactly How
- Why the US Government Just Banned This Chinese App’s Core Technology
© AiwalaNews | Global Tech & Privacy Edition | April 2026