You open Netflix. Before typing a single search, a perfectly curated grid appears warm, familiar, almost eerily personal. You open YouTube and it already knows you’re in a late-night rabbit hole mood. You unlock Instagram at 11 p.m. and the Reels begin flowing, one into the next, like a playlist built just for you.
None of this is accidental. Behind every “Recommended for You” row sits a multi-billion-dollar algorithmic machine that, in certain measurable ways, knows you better than your closest friends do.
What Is a Recommendation Algorithm Really?
At its core, a recommendation engine solves a deceptively simple problem: given one user and a catalogue of millions of items, predict which item that user will most want to engage with next. The word “engage” is critical it does not mean find most useful, or enjoy most in hindsight. It means: click, watch, scroll, linger.
Most modern systems begin with a technique called collaborative filtering finding users who behave like you, then surfacing what they consumed. Netflix’s “people who watched X also watched Y” is its most recognisable face. But that’s the 2005 version. Today’s engines layer deep neural networks across hundreds of behavioural signals simultaneously, recalibrated in real time, every session, every scroll.
80% of everything watched on Netflix is driven by its recommendation engine. 70% of YouTube’s total watch time originates from algorithmic suggestions not from users searching. Amazon attributes over $1 billion in annual incremental sales directly to its “Customers also bought” system.
The Signals Feeding the Machine
Every interaction you make online is a data point and not merely what you click. The behavioural fingerprint these systems build includes:
- Dwell time – how many seconds you spent on a post before scrolling past
- Replay signals – whether you rewound a video or re-read a passage
- Session context – what you watch on mobile at midnight versus desktop at noon
- Implicit rejection – content you saw but deliberately skipped
- Social graph proximity – who you message privately, not just who you follow publicly
- Ad hesitation – ads you lingered on for two seconds before dismissing
This fingerprint is far more granular than any preference survey. You never filled out a form telling YouTube you prefer long-form geopolitics at 1 a.m. You simply behaved that way and the algorithm filed it.

Why the Algorithm Is Built to Addict, Not Satisfy
This is the part Big Tech rarely discusses in earnings calls. Recommendation systems are optimised for a business objective and that objective is engagement: time on platform, ad impressions, subscription retention. A system that leaves you satisfied and ready to close the app has, by its own metric, failed. A system that leaves you slightly anxious, curious, or stimulated enough to tap “next episode” has succeeded.
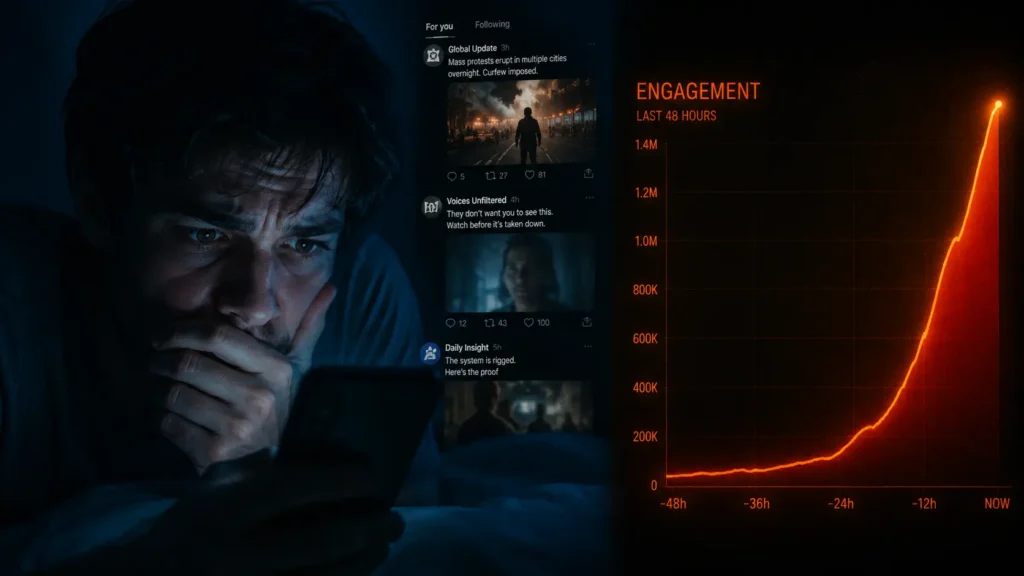
Research documented in peer-reviewed publications including Nature Machine Intelligence describes what scholars call the “engagement trap”: recommendation engines learn surprisingly quickly that content triggering mild negative emotion outrage, envy, social anxiety generates longer sessions than purely enjoyable content. The algorithm does not intend to distress you. It simply discovered that distress correlates with scrolling, and scrolling correlates with revenue.
A 2023 study by the Center for Humane Technology found that socially activating content particularly posts triggering moral outrage generated 2–3× more reshares and comment activity than neutral posts of comparable factual quality. Algorithms amplified it accordingly.
The Filter Bubble You Never Opted Into
When a system learns your preferences with sufficient precision, it begins to narrow the world it shows you. This is the filter bubble introduced as a concept by researcher Eli Pariser in 2011 and extensively validated since.
You stop encountering views that contradict yours not because you asked to be shielded, but because content that confirms existing beliefs generates more engagement from you than content that challenges them. The algorithm made that choice on your behalf, silently, in milliseconds.
A landmark 2023 paper published in Science, using data from Meta’s own internal studies, found that Facebook’s algorithmic feed measurably increased political polarisation among users who relied on it as a primary news source, compared to users shown a reverse-chronological feed. The feed wasn’t neutral. It was, functionally, an opinion amplifier.

What You Can Actually Do
Awareness is the first lever. The second is deliberately disrupting your own behavioural patterns. Search outside your usual domains. Use “Not interested” and “Don’t recommend this channel” functions aggressively these signals genuinely recalibrate ranking models. Seek platforms that offer chronological feeds.
In the EU, the Digital Services Act (2022) now legally requires major platforms to offer users a non-personalised feed option. That right is worth exercising. Regulators in the UK, US, and India are actively examining whether optimising algorithms for engagement when that engagement demonstrably harms users constitutes an unfair commercial practice.
The next generation of recommendation engines may be legally required to optimise for user satisfaction rather than mere attention capture. That shift cannot come soon enough.
The Bottom Line
Recommendation algorithms are not neutral tools. They are precision persuasion machines, built to maximise a business metric using the most intimate data available your behaviour when you think no one is watching. Understanding how they work is not a technical exercise. It is an act of digital self-defence.
The feed is not a mirror. It is a lens and someone else is holding it.
📌 Read Also:
- How Credit Card Companies Know You’re About to Miss a Payment — Before You Do
- Your Phone Decides How Much Battery to Give Each App — And You Never Agreed to It
© AiwalaNews | Global Tech & Privacy Edition | April 2026